Heap Overflow and integer overflow
Attacks on applications are among the most common actions that hackers carry out. By taking advantage of an error in a program, an intruder can gain the access rights under which the program started. Programming bugs can leave data from the process memory open to attack. This chapter demonstrates how hackers use this type of error.
Memory segments
Every program has a specific amount of RAM memory at its disposal. When a program starts up, the system kernel creates a memory area for it and allocates memory to this as needed. One part of this memory contains the executable code of the program; another might contain its static data. This process is known as the division into memory segments. As we have already mentioned, a program uses five segments during its operation:
| Program code (text) |
| Initiation data (data) |
| Non-initiation data (bss) |
| Space for dynamic memory (heap) |
| Stack |
They are located in the address space of the process in this order. The program code is placed on the very top, while lower addresses are added to the stack.
We will now take a closer look at the following program to learn what the individual segments are for (/CD/Chapter8/Listings/test.c).

Our program uses four memory areas of 16 bytes capacity. The first of them is the the segment data[16] table, to which we immediately assign the value “” (that is, we leave it empty). This means that this variable is initiated. In addition, we declared it to be outside the function body, that is, it is global. This type of data is stored in the data segment. Then, already in the main() function, we declare the segment stack[16] table. This is created dynamically during program execution, and for this reason it is placed in the stack segment. To the segment heap pointer we assign the value returned by the malloc(16) function. This function allocates memory in the heap segment. Later on we will take a closer look at how it works. The last variable we declare is segment_bss[16]. It is a static variable, which we define in the declaration using the word “static.” Thanks to this it will be placed in the bss segment. As we can see each segment is indispensable for the program to function. We can also check for their presence by using the objdump program.
bash-2.05b$ gcc -o test test.c
Next, in order to display the program segments we will use the objdump –h option:
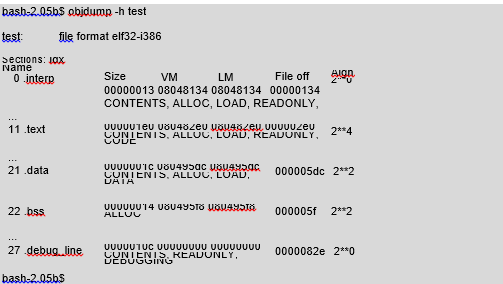
As we can see, they are very numerous, as many as 27. These are not, however, only memory segments, but also segments of a binary file. Their initial addresses and sizes are constant, and therefore they can be written to the binary file. Heap segments and stack segments are dynamic, meaning that they change their size. Their initial address depends on the system, and therefore the information on those segments is not included in the binary file.
With the objdump program we can also check that our variables are located where we expect:

We can thus determine the addresses of the static and global variables. The dynamic variables placed on the stack or heap are created during the program function, so there in no possibility to access them on the basis of investigating the binary file itself.
Another program segment that we mentioned is text. It contains the executable code of the program; in other words, the subsequent instructions of the processor. Therefore no variables are stored in it. We can display its content also using objdump:

As we notice, the data here do not mean much to a human, but are understandable to a processor.
In order to see a more legible version of this segment, we can change it into assembly-language instructions using the -d option:


Here, objdump has demonstrated that there are many functions in the program (their body in the assembly language has been replaced with ellipsis). As programmers we have written only the code of the main() function. The rest has been added by the gcc compiler and constitutes part of the text segment.
Let’s have a closer look now at the heap segment.
Heap
As we know, to allocate memory in the heap segment we use the malloc() function. This is not, however, a function used by the kernel, but by the C language library. The target function made available by the kernel, used to allocate memory in the heap, is brk(). It assumes a new address for the end of the heap as a parameter. If we give it an address greater than the current end, it will allocate a new memory area. At other times, when we enter an address smaller than the end, a corresponding amount of memory will be released. Let’s assume we want to allocate 16 bytes of memory to the heap. In order to do that, we have to discover the current heap end and to transfer to the brk() function a value greater by 16. To discover the point where the heap ends, we can use the sbrk() function, which we transfer in the 0 parameter. Here is a program that executes these operations (/CD/Chapter8/Listings/test2.c):

We will now test our program to see if it really does allocate 16 bytes of memory:

As we can see, after executing the brk() function, the address of the heap end changes by 16; in other words, memory has been assigned. Defining the address of the heap end each time and transferring the appropriate argument of the brk() function is unnecessary. We can use the sbrk() function of the C library and enter the amount in bytes that we want to allocate. It will then perform these operations for us. The best solution, however, is to use the malloc() function, as in our first example. This located in each compiler, meaning that the programs written with it will always work. In the Linux system the malloc() function performs similar operations as sbrk(), but it also takes care not to allocate small memory areas too many times, to prevent memory fragmentation. Subsequent memory areas are allocated immediately next to each other. This carries with it some risk as described next.
Buffer overflow
After a successful termination, the malloc() function returns the address to the new memory area. Its subsequent calls allocate memory immediately next to previous areas. If our program copies data to the first buffer without checking its size, it can cause the second to be overwritten. We will now analyze the following program (/CD/Chapter8/Listings/heap.c):


At the beginning we allocate two buffers: buf1 and buf2. The first one is located under buf2 in the process memory. Next, we calculate the distance between buf1 and buf2 and assign the result to the “how much” variable. In this way we will know how many bytes of data we have to transfer to the program for copying so they overwrite buf2. The strcpy() function, which copies data from the first argument of the program to buf1, and the use of which is therefore quite risky, is located at the end of the code. Let’s test our program:

The first byte of buf2 is now the zero byte inserted by the strcpy() function, therefore, the program states that buf2 has no content. The content of the buffers after overwriting looks like this:
| BBBBBBBB – buf1 | BBBBBBBB – gap | 0AAAAAAA – buf2 |
All we need to do is transfer a character sequence longer than 16 bytes, and the result will be visible:

After transferring 20 B characters, buf2 assumed the “BBBB” value, even though nowhere in the program did we perform such an entry. Our program in the example is therefore susceptible to heap overflow attacks. Now, we will see how we can put this to practical use.
An example of heap overflow
To take advantage of a heap overflow error in practice we have to have something to overwrite. On the heap there are no pointers that we can overwrite, as was true in the case of stack overflows, which we discussed in an earlier chapter. We can overwrite only that which we have already created ourselves. A frequently used technique is the overwriting of the names of the files used. They are often stored on a heap.
Let’s take a look at the program below that prints an appropriate amount of lines from the “file.txt” file (/CD/Chapter8/Listings/heap2.c):


The error is visible immediately. The data transferred in the first program argument are copied without restriction to the “how much” character buffer. If we transfer the right amount, this will overwrite the memory area for the “file” pointer. At the beginning, we can create a file with the name “file.txt” to ascertain how the program works.

This reads as many lines from the “file.txt” file as we enter in the first argument. We will now try to overwrite the file name in such a way that the program will open another one, for example /etc/passwd.
From the previous example we know that there is a gap of 8 bytes between buffers allocated by malloc(). We will, therefore, transfer 24 bytes to our
program to fill this, followed by the path to the file. The first fill character will be the line number we want to read:

We transfer a long byte sequence as the program argument, but the atoi() function converts it into number 5, due to its first character (5). After subsequent fill characters have overwritten unimportant memory areas, we enter the path to the target file. As we can see, everything has gone just as we had planned. Now we will confer administrator privileges on our program:

For now this will work as the root user. If this program were located in a real system, we could gain, for example, access to encrypted system passwords:

If the password is easy, we can use the password cracker to gain full access to the system.
An example of bss overflow
The problem of buffer overflow is also an issue for the bss segment. If we do not limit the data being copied to the buffer located in the same segment, they will overwrite other memory areas not assigned to specific variables. The most frequent case of bss overflow is “function pointer overflow.” Let’s have a look at the following example (/CD/Chapter8/Listings/bss.c):
#include <stdio.h> #include <stdlib.h>

On the basis of the first argument, the program assigns an appropriate value to the function pointer. Next, it copies the function parameters into the static buffers and transfers them during the function call. The a and b buffers and the pointer of the func function are located in the bss segment. Before calling func(), the program executes strcpy(), which, as we already know, can overwrite the buffer.
Let’s test our program.
bash-2.05b$ ./bss add 2 2
4
bash-2.05b$ ./bss multiply -32 92
-2944
bash-2.05b$
This program for short data strings works perfectly. But what happens if we transfer a long character sequence as the third argument?
bash-2.05b$ ./bss multiply -32 AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Violation of memory protection (core dumped)
The program will report a memory protection error. The A characters have been copied into the “b[SIZE]” buffer. The buffer size was insufficient to store such a sequence, and it therefore overwrote the memory area outside itself. The value of the func() pointer was the content of the overwritten memory. After calling func(), instead of jumping to the appropriate function, we jump to the address “AAAA.” We will now check this using the gdb program:
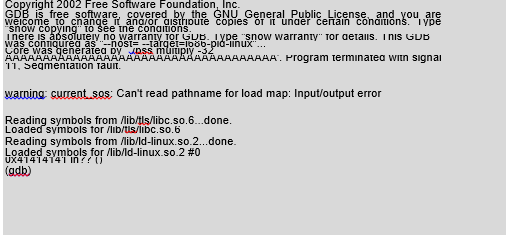
As we can see, our assumptions proved correct. The address 0x41414141 is not part of the memory assigned to our process, so during the attempt to access it, the system kernel killed our program. The example of a bss overflow shown above gives us more opportunities than a heap overflow would. If we overwrite the function pointer, we can direct the operation of the whole
program. Let’s try jumping to the subtract() function instead of the add() function by overwriting the func() pointer with its address. At the beginning we define the address of the divide() function:
gdb) print ÷
$1 = (<text variable, no debug info> *) 0x8048480 <divide>
We know that it is 0x8048480. Now, using a short Perl insert we transfer arguments we have prepared to the program:
bash-2.05b$ ./bss add 8 0002`perl -e ‘print “\x80\x84\x04\x08″x10’` 4 bash-2.05b$
Our second number to add is 0002<address_divide_function>; that is, after calling the atoi() function, simply 2. The atoi() function will change the character sequence into a whole number until it reaches the first character that is not a number. As we can see, we managed to induce subtraction instead of addition, despite the first argument commanding the program to execute something completely different. We should bear in mind that the address of the function being called is to be entered from the end.
We have commanded the program to execute operations due to the overwriting of the function pointer, but this has not yet given us anything of real benefit. Instead of using the program function, in the call argument we can transfer the binary code of our function, to which we will then jump. Our function will be used to start up the /bin/sh shell. As we know, such a representation of the function in the form of characters is called a shellcode. The following listing shows the exploit code that starts up the shell using the error in our program (/CD/Chapter8/Listings/exp_bss.c):


We place our shellcode in the environment variable so that determining its address in memory will be easy. Then we start up a vulnerable program with arguments “add,” “2,” <buffer with shellcode addresses>. The shellcode addresses overwrite the func() pointer that, instead of print(), runs our shellcode. Let’s check if it will work:
bash-2.05b$ gcc -o exp_bss exp_bss.c bash-2.05b$ ./exp_bss
sh-2.05b$ exit exit
bash-2.05b$
As can be seen, we have managed to start up the sh shell without significant problems. If the “bss” program were working with root privileges, we would obtain full access to the system resources.
In summary, like other errors, serious hackers should investigate heap and bss overflow errors, even though that they are often impossible or difficult to take advantage of. A lot of information is stored on the heap, and overwriting it can bring us benefits. Apart from the buffers created by our program, there is also information stored, for example, by the libc library. A clever hacker will use anything, even the smallest gap, to penetrate the system.
Is this question part of your Assignment?
We can help
Our aim is to help you get A+ grades on your Coursework.
We handle assignments in a multiplicity of subject areas including Admission Essays, General Essays, Case Studies, Coursework, Dissertations, Editing, Research Papers, and Research proposals
Header Button Label: Get Started NowGet Started Header Button Label: View writing samplesView writing samples